
The next release of Sphider, 3.2.0-MB, will feature two new enhancements. The first will be the ability to show the query score using a 0-5 star system, using half-stars. The options to either show no score, or to show a score as a percentage (100% being the highest) will remain.
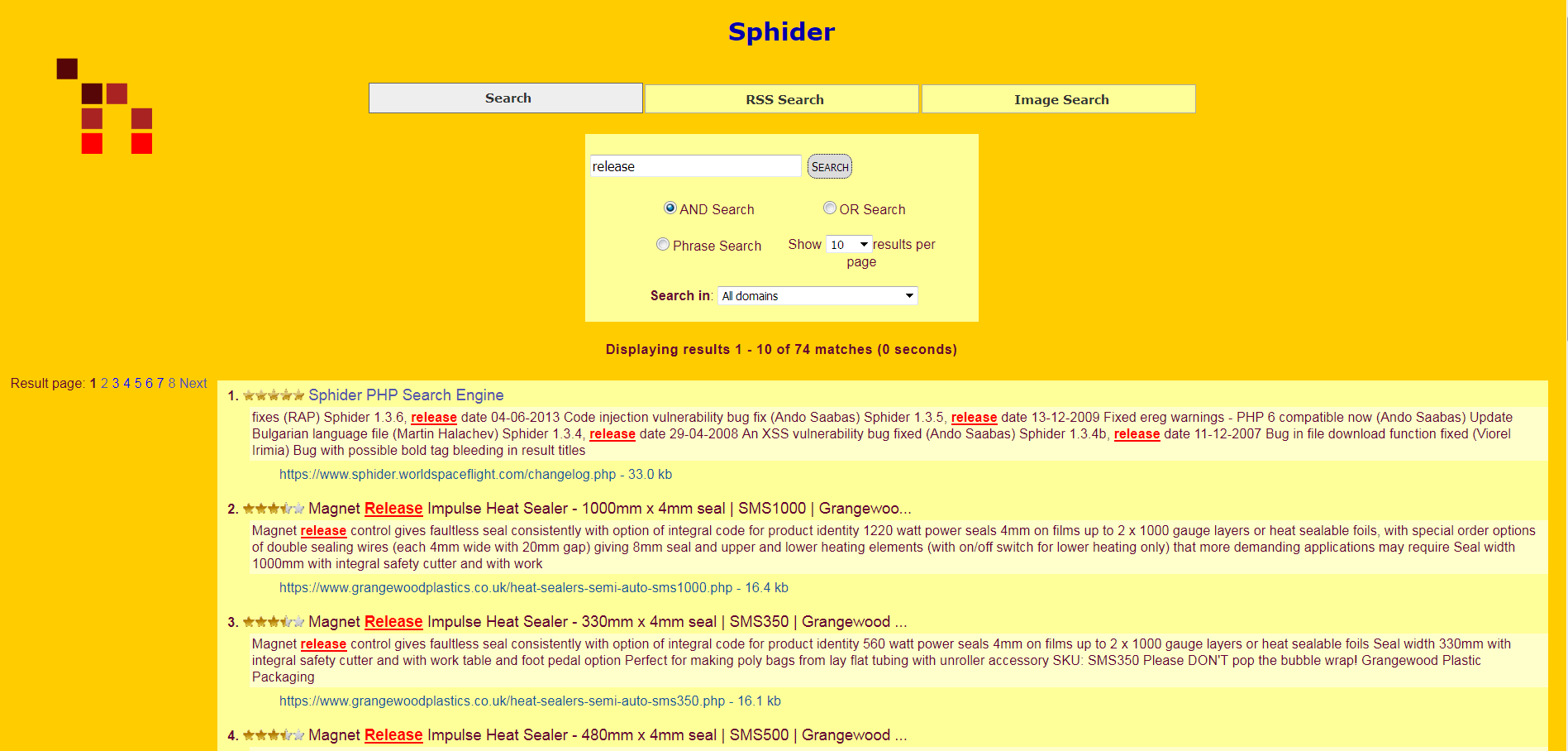
The second enhancement is the addition of the ability to limit the number of query returns by percentage. Currently, a query will find every possible result. Scores range from 100% to 0% relevancy. In 3.2.0-MB, a minimum relevancy can be set. Users can choose from 0, 20, 40, 60, and 80% relevancy as the minimum. The higher the number, the fewer results will be returned. In the example shown above, the query produced 74 results. If the floor had been set at 20%, the number of results would be reduced to 12. A floor of 40% further reduced the results returned to 7,
Along with a couple minor bug fixes, Sphider 3.2.0-MB will be coming in perhaps early June.