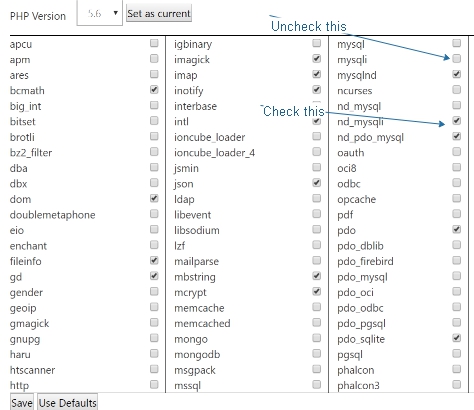
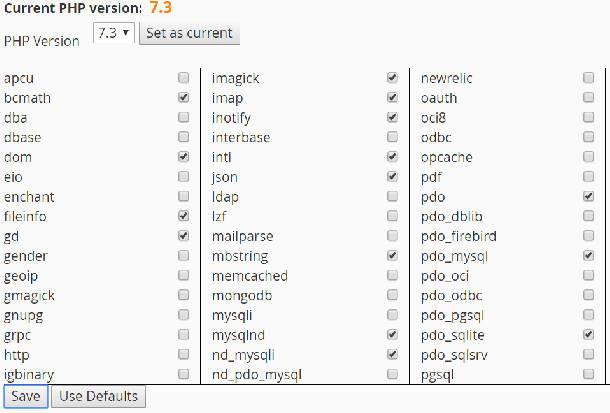
Some websites just don’t index very well. Here are some examples, and a solution if there is one.
You are trying to index “http://somesite.com/” and you get an initial 301 error and get no further. You try the hack for the fake 301 errors (my last post), but that doesn’t work. Cause? There just might be a REAL 301 error. A browser will take the “http://somesite.com/” and follow the redirect to “https://somesite.com/”! Sphider isn’t that smart. The fix is to charge Sphider to look for https instead of http.
You try to index “https://somesite.com/”, the initial page indexes, but no further pages are found, or some pages are found but not others. The likely cause is that the website uses https and http interchangeably. That might work for a browser, but not for Sphider. As a Sphider user, there isn’t much you can do except hope the website owner does some editing and makes his/her references consistent.
After the first page, some site will not index very well. A possible cause is a heavy use of JavaScript in forming the pages, particularly the references (links). Sphider does not index JavaScript. As a Sphider user, there is nothing you can do.
You are indexing a site and you get a lot of garbage results. Sphider is built for full four-byte UTF-8. Not all websites have UTF-8 pages, and that is fine because Sphider knows that and performs conversions if needed. Not every web page tells Sphider what encoding it does use, and that is okay, too. Sphider is pretty good at figuring these things out. But sometimes, thankfully not common, a web page will be written with one encoding but explicitly state that is a different encoding. For example, a page written in Windows-1252 but declaring it is UTF-8 isn’t going to be converted to UTF-8 because Sphider has been led to believe it already is! Result is going to be some strange index results. Even worse, a page is UTF-8 but says it is something else… Believe me, converting UTF-8 to UTF-8 is going to be a mess! As a Sphider user, nothing you can do about a poorly written web page.
Another scenario is that you are indexing away and Sphider suddenly quits. You investigate and finally find it exited with a PHP exhausted memory error. After looking further, you see the error occurred on a file that Sphider shouldn’t even be processing. In one instance, I had PHP crash while trying to index a .swf (flash) file. Sphider SHOULD have reported a .swf file as “Not text or html” and gone on to the next page. I tore my hair out trying to see what the issue was, and it turns out the website was sending an erroneous header report the WRONG “Content-Type:”. I had other strange halts with PHP errors on that same website, and the cause each time was an incorrect header stating the content type. Shy of writing a huge function to determine content type from the file extension instead of reading the headers sent, the only thing a user can do is identify all the page’s problem url’s and put them in the “Must not” section of the site settings. As an aside, I am clueless as to how a website can send the wrong file headers. Anyone out there have insight on this?